要製作迴圈,一定要先針對它的定義有共識。
常見迴圈有2種不同的架構過程,要知道自己在做的是哪一種。
同樣一套底階資料,同樣一套處理方式,但不同的變數,重複一直跑。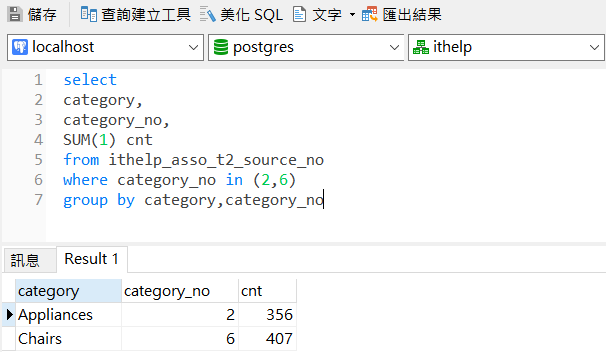
例如以上範例,我想從資料表取某兩項商品出來,以利後續運算二者的關聯數據,但我整個分析又不是只看這兩個,所以第一次取商品1和商品2,第二次取商品1和商品3,一直取到最後一次是商品16和商品17。如果有17項商品,就有136種(1+2+3+...+16=136)不同的二商品組合,因此總共必須取136次。像是上圖範例取的是商品2和商品6。
用的底階資料是一樣的,也都是挑兩項商品,但挑的內容不一樣,重複到所有組合被我挑完為止。可是我總不可能人工一直去改【in (2,6)】裡面的數字,兩者都從1改到17吧?這時候就是需要用上迴圈的時刻。這是第一種迴圈模式。
不相同的底階資料,同樣一套處理方式,重複一直處理。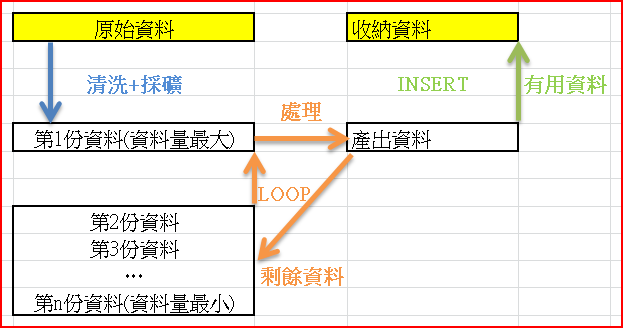
例如上圖概念,資料來源相同,但經過第一次整理之後,把【有用資料】產出並收納,【剩餘資料】已經與第一次整理前不同了(資料量比較少),可是必須再透過原本的處理方式再處理,同理再產出、一邊收納一邊剩餘資料再處理......。
此法的關鍵問題在於,從第2份資料開始,它並不是事前就能確認的資料,第2份必須等第1份處理完之後才有、第3份必須等第2份處理完之後才有......以此類推。這是第二種常見的迴圈。
資料處理那串程式碼是固定的,換句話說,它取用的資料名稱是固定的(from 固定的資料名稱)。因此,上面三個橘色箭頭的Loop過程,必須包括:
insert table:收納資料
drop table:將上一次處理的data捨棄掉,因為已經處理完了,要處理剩餘的。
create table:將這一次要處理的data建上,才能讓資料處理第2次、第3次......
為何是用drop + create?這邊可能有人會有不同意見,認為應該要用 truncate + insert。
優劣是這樣看:如果你已經非常確定你的產出欄位不會變,已經是一個很穩定在運作的內容,truncate + insert的效能是比較好的;但是如果還在建置期,甚至就算建置完了,有增減欄位的可能,那我一定建議你用drop + create,否則每次欄位變動,你會非常痛苦......。
事實上,在drop + create還跑得動之前,除非你數據真的大到不能再這樣處理,否則在跑得動之前,我都強烈建議用drop + create。不過我的出發點都是SQL撰寫人員的角度,如果有DBA專家看到這裡,有其他不同的顧慮,非常歡迎提出來討論看看,也很可能是小馬了解得不夠深入。
也因此往後小馬的SQL,你都會看到drop走在前面,然後接著create。
小馬自己對這二種迴圈有個小暱稱,第一種叫做「內迴圈」、第二種叫做「外迴圈」。應該不是廣泛的用法或專有名詞,但我曾經很努力要找到這兩種迴圈到底被稱做什麼,發現能參考的資料少之又少,命名也不直覺,所以就容小馬任性,先以內外迴圈來稱呼這兩種類型吧!
往後我打算製作三個主題,包括【關聯分析的底階資料】、【英文文字雲的底階資料】、【中文文字雲的底階資料】,三者依序會用上內迴圈、外迴圈、內迴圈+外迴圈。進行的步驟都是1天講解完整的處理程序,1~2天放上SQL詳述,請各位拭目以待,讓我們一起把迴圈運用得淋漓盡致吧!
上一篇:
SQL迴圈實作 -1.慣用寫法
下一篇:
SQL迴圈實作 -3.關聯分析的處理工廠1


 iThome鐵人賽
iThome鐵人賽